Mobile Paywall A/B Testing: A Practical End-to-End Guide
Learn how to plan, run, and analyze mobile paywall A/B testing with this end-to-end guide. Covers hypothesis, implementation, analysis, and common pitfalls.
Many teams don't have a paywall problem. They have a decision problem.
Revenue is soft, the onboarding funnel looks healthy enough, and every paywall change turns into a long debate between product, growth, design, and engineering. One person wants a new annual-first layout. Another wants a trial. Engineering wants fewer last-minute requests. Finance wants cleaner reporting. Nobody wants to ship a monetization change blind.
That's where mobile paywall A/B testing stops being a tactic and becomes operating discipline. The point isn't to test random screens until something works. The point is to create a repeatable system for deciding what to test, how to launch it safely, how to measure it properly, and how to turn each result into the next experiment.
Beyond Guesswork in Mobile Monetization
A familiar scenario plays out in a lot of apps and games. The team has real usage, strong reviews, and decent retention in early sessions, but paid conversion stalls. The paywall gets blamed because it's visible, but the actual issue is usually that nobody can answer basic questions with confidence.
Which audience is seeing the paywall? What offer are they getting? Is the annual plan too aggressive for first-session users? Is the problem the screen itself, or the trigger that sends users there too early? When teams can't answer those questions, they fill the gap with opinions.
What usually goes wrong
The first failure mode is cosmetic testing without a monetization hypothesis. Teams swap colors, move a button, or rewrite a headline without defining what user objection they're trying to address.
The second failure mode is operational. A simple paywall change needs design handoff, app changes, QA, release coordination, and store approval. That friction pushes teams toward fewer tests, which makes every launch feel riskier.
A third issue is measurement. Conversion rate gets all the attention because it's immediate, but subscription businesses don't make money from immediate action alone. They make money from users who start, stick, renew, and don't churn out after a trial.
Practical rule: Treat the paywall as part of a monetization journey, not as a standalone screen.
That shift matters. A paywall is influenced by the screen before it, the segment seeing it, the purchase products connected to it, and the messaging after dismissal. If those parts aren't coordinated, test results get noisy fast.
What a disciplined team does instead
Strong teams run mobile paywall A/B testing the same way they'd run a feature rollout or pricing decision. They define the business question, isolate variables, control eligibility, and agree on success criteria before the test goes live.
That process also forces better cross-functional work:
- Product managers define the hypothesis, audience, and business outcome.
- Engineers make sure events, purchase states, and experiment assignment are reliable.
- Growth teams decide what offer, copy, and timing to test.
- Analysts or monetization owners review revenue quality, not just front-end conversion.
If you're trying to build that kind of system, it's useful to anchor paywall work inside a broader revenue optimization approach for mobile products, because pricing, entitlement, onboarding, and lifecycle messaging all affect the result.
The shift that changes everything
The turning point is usually simple. Stop asking, "Which paywall looks better?" Start asking, "What uncertainty is most likely suppressing revenue?"
That question is more useful because it forces a real choice. Maybe new users don't trust the annual commitment. Maybe high-intent users need the paywall earlier. Maybe your pooled global test is hiding a country-level win. Maybe a variant lifts starts but attracts low-quality subscribers.
Once the team works that way, the paywall stops being a black box. It becomes an instrumented decision surface with clear inputs and measurable outputs.
Formulating Hypotheses That Actually Drive Growth
The best paywall experiments don't start with design. They start with uncertainty.
If your team already knows users understand the offer and aren't buying, then testing a new visual treatment might help. But most apps aren't there. The bigger unknown is usually somewhere else: audience, package, trial framing, or timing.
Start with the biggest uncertainty
A useful hypothesis names four things: the audience, the change, the expected behavior, and the reason that behavior should change.
Good hypotheses sound like this in practice:
- Audience-led: New users who complete onboarding but haven't hit core value may respond better to a softer offer than power users who already rely on the app.
- Offer-led: An annual-first paywall may work for users with high intent, while a monthly-first option may reduce hesitation for colder traffic.
- Timing-led: Showing the paywall after a completed action often performs differently from showing it on first app open.
- Objection-led: Adding clearer cancellation language or feature proof may reduce hesitation more than a full redesign.
Weak hypotheses usually sound like "let's try a fresh design." That isn't a business hypothesis. It's a creative prompt.
Use a practical checklist before you build variants
When I review paywall backlogs, I sort ideas with a simple filter. Not "is this easy to ship?" but "if we're wrong about this, how expensive is that mistake?"
A working checklist:
- Audience: Which user segment should see this? First-session users, returning users, purchasers of a related item, players who failed a level repeatedly, readers who hit a content threshold?
- Offer: What is the user being asked to buy? Full subscription, starter package, premium access, ad-free upgrade, consumable bundle, season pass?
- Price and package: Is the issue the product mix rather than the screen? Monthly versus annual often changes perceived commitment.
- Trial framing: Does "start free trial" create the right expectation, or would a different framing reduce confusion?
- Proof: What evidence does the user get that premium access is worth paying for?
- Objection handling: What stops the purchase right now? Commitment, trust, price clarity, feature clarity, or timing?
- Timing: Which event triggers the paywall? A blocked action, milestone, feature tap, content meter, or level completion?
- Design hierarchy: Does the screen direct attention to the intended package, benefit, and action in the right order?
Keep the test narrow enough to learn
One widely used baseline is to test a single element at a time and use a statistically valid split such as 50/50, or in multi-variant tests roughly 33%/33%/34% or 25%/25%/25%/25%. The same guide notes that a typical test may use about 2,000 paywall exposures to justify a 50/50 allocation, and that only about 20–30% of paywall tests typically produce improvements, which is exactly why disciplined prioritization matters in the first place, as described in this mobile paywall testing guide.
Most paywall ideas won't win. A good testing program still wins because it learns quickly and avoids expensive false confidence.
For product and engineering teams, that means resisting the temptation to bundle everything into one "better paywall." If you change copy, layout, pricing emphasis, trial language, and trigger timing all at once, you may get a result, but you won't know what caused it.
A strong hypothesis reduces ambiguity before the experiment even starts.
Designing a Statistically Sound Paywall Experiment
A solid hypothesis still fails if the experiment design is sloppy, often leading teams to lose trust in testing. Not because A/B testing doesn't work, but because the setup lets too many variables move at once.
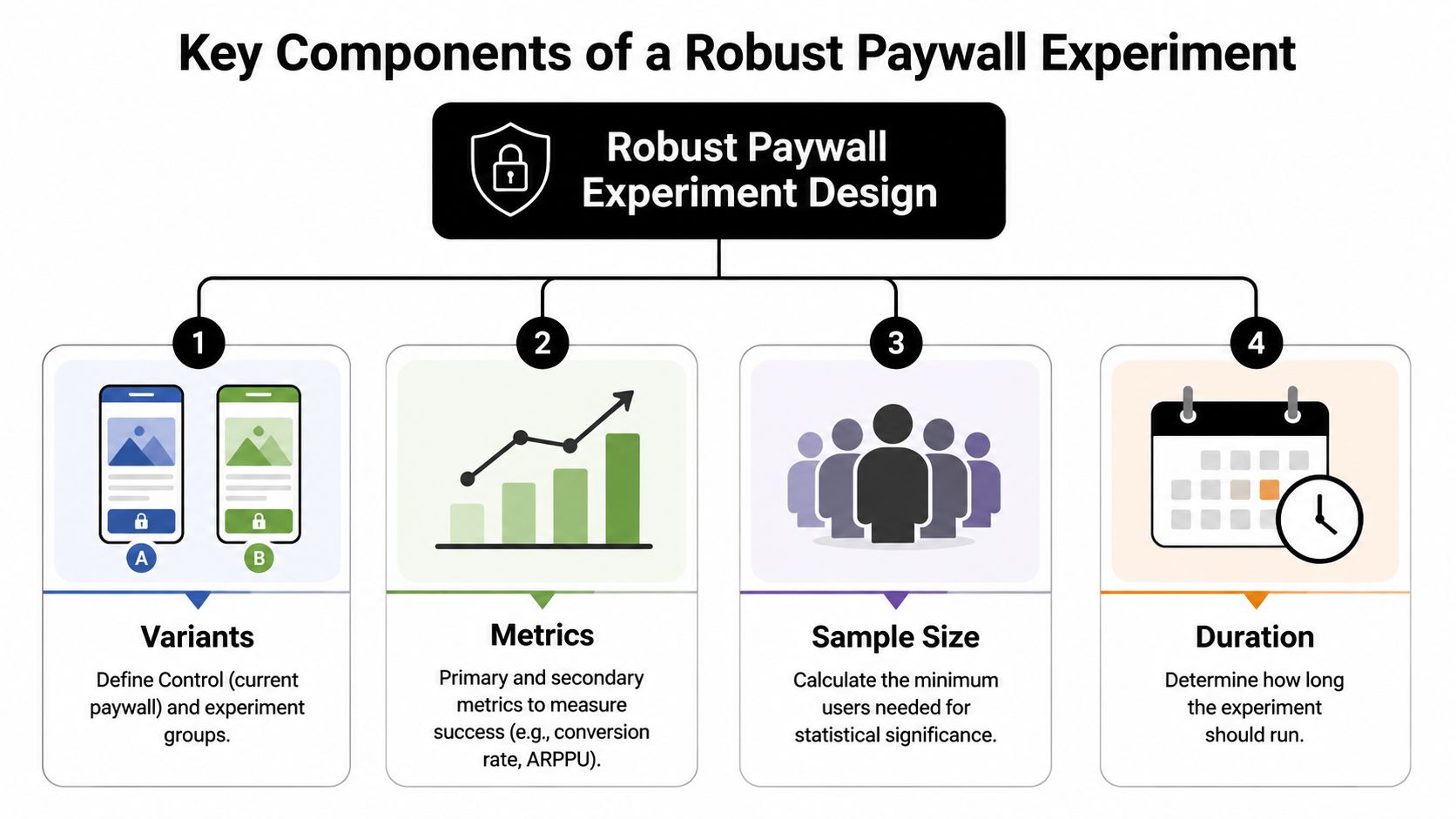
Define the experiment before launch
Before anyone publishes a variant, lock these decisions:
| Component | What to define |
|---|---|
| Eligibility | Which users can enter the test, and which users are excluded |
| Variants | Control versus variant, with exact differences documented |
| Primary metric | The single metric used to decide the test |
| Guardrails | Metrics that would block rollout even if the primary metric improves |
The primary metric should reflect the business question. If you're testing trial framing, trial starts may matter. If you're testing price presentation, revenue per exposed user may be more useful. Guardrails matter because some "wins" are expensive. Support complaints, cancellations, or low-quality subscribers can erase the apparent gain.
Control the assignment logic
A lot of noisy experiments come from weak eligibility rules. If users can see multiple variants on different sessions, if assignment resets after reinstall, or if platform behavior differs between iOS and Android, your comparison gets contaminated.
Product and engineering should agree on assignment behavior up front:
- Persist assignment: A user who lands in control should stay in control for the test window.
- Keep triggers stable: Don't change the event that launches the paywall mid-test.
- Match store products carefully: The UI variant and the underlying product mapping have to stay aligned.
- Log every step: Exposure, dismiss, purchase intent, purchase success, restore, entitlement grant, and post-purchase state all need clean events.
Duration matters as much as split
Teams usually focus on split first and timing second, but the run window matters just as much. Short tests often capture day-specific behavior instead of a stable signal.
Decision filter: If your experiment design can't survive a skeptical review from engineering and finance, it isn't ready to launch.
A good experiment plan should be boring to audit. Someone should be able to read it and understand who saw what, when they saw it, what counted as success, and what would invalidate the result.
That discipline saves time later. It prevents the familiar post-test argument where one team cites conversion, another cites revenue, and engineering points out that assignment logic changed halfway through the run.
Implementing Tests Without App Store Delays
The fastest way to kill experimentation is to tie every paywall change to a full mobile release cycle.
If growth wants to test new copy on Android, product wants a different trigger on iOS, and design wants to reorder plans in a React Native build, nobody should be waiting on a store submission for each iteration. The implementation model needs to separate paywall logic from release cadence.
The practical architecture
The clean setup is server-driven or remotely published paywall delivery. Engineering integrates the runtime once, exposes the right events and purchase states, and then the paywall screen, trigger rules, audience logic, and experiment assignment can be updated without shipping a new binary.
That pattern works across iOS, Android, React Native, Flutter, Unity, and Unreal if the runtime is built for cross-platform delivery rather than a single native stack.
A typical implementation looks like this:
SDK integration
Engineering adds the platform SDK, wires identity, purchase state, entitlement refresh, and analytics events.Trigger instrumentation
The app emits meaningful events such as onboarding complete, feature locked, level failed, article meter reached, or premium tab viewed.Remote flow definition
Product or growth configures which audience qualifies, which paywall appears, and which variant assignment rules apply.Publishing and rollback
Changes ship remotely, with the ability to pause or revert if a bug or metric issue appears.
What product and engineering should agree on
This part is usually where good teams separate from chaotic ones. A remote paywall system only works if ownership is clear.
| Team | Responsibility |
|---|---|
| Engineering | SDK integration, event integrity, billing and entitlement correctness, fallback behavior |
| Product | Hypothesis quality, trigger strategy, rollout criteria |
| Growth | Variant setup, segmentation, copy, offer logic |
| QA | Variant rendering, assignment consistency, purchase path validation across platforms |
One useful pattern is to keep the paywall inside a broader in-app journey rather than treating it as an isolated modal. That means the trigger, branch rules, dismissal path, survey path, and post-purchase confirmation all live in one remotely controlled flow. Teams that want that model often use tools with a visual in-app flow builder for mobile journeys.
Among the available options, Nuxie fits this approach as a provider-agnostic platform that can run in-app experiences, experiments, analytics, billing, purchase sync, and entitlement flows together without requiring a revenue-share fee on billing or entitlement data. The practical benefit for paywall work is simple: the trigger, audience, variant, and result reporting can live in one system instead of being spread across multiple dashboards.
A short walkthrough helps make the implementation pattern concrete:
Common implementation mistakes
The failures here are rarely strategic. They're usually operational.
- Mismatched products: The paywall says annual-first, but the billing product order doesn't match the UI.
- Leaky eligibility: Users qualify for the experiment after purchase or after already seeing another variant.
- Weak fallback behavior: If remote config fails, the app shows nothing or shows the wrong default.
- Untracked dismissal paths: Teams log purchases but not closes, restores, or follow-up actions.
- Platform drift: The iOS paywall and Android paywall look similar but don't behave the same way.
If those basics aren't reliable, your experiment results won't be either.
Analyzing Results and Avoiding Common Pitfalls
The risky moment in paywall testing is not launch day. It is the readout meeting, when a team sees an early lift in trial starts and starts arguing for rollout before checking whether the variant improved the business.
That usually happens because the experiment was instrumented across multiple systems. The paywall variant lives in one dashboard, purchases in another, renewals in a third, and nobody has a clean event trail from eligibility to revenue. If you are running paywalls through Nuxie with remote config and SDK triggers across iOS and Android, use that setup to your advantage. Tie each result back to the exact variant, product set, trigger, and audience rule that produced it.
Read the report like an operator
A useful test report lets product, engineering, and growth review the same facts without filling gaps from memory. It should answer two questions fast: what changed, and what happened after the change.
Include at least:
- Eligible users: Who qualified for the test
- Exposures: Who saw the paywall
- Purchases or trials: The immediate monetization action
- Revenue per exposed user: A better read than conversion alone
- Duration: How long the test ran without variant or audience changes
- Decision threshold: The statistical standard set before launch
- Variant log: The exact copy, layout, offer, trigger, product IDs, and audience logic for each version

One more rule matters here. Freeze the variant definition during the test. If someone changes copy, swaps package order, or adjusts eligibility in remote config halfway through, the result is no longer clean. Teams do this more often than they admit, especially when product and engineering are shipping quickly.
Measure beyond the first purchase event
A paywall can improve starts and still hurt subscription economics. Annual take rate can fall. Lower-priced packages can cannibalize better ones. Refunds, billing failures, and short-lived trials can erase the headline win.
That is why the primary metric should reflect commercial value, not just top-of-funnel movement. Many teams use revenue per exposed user or a similar monetization metric as the decision anchor, then review retention and renewal signals before making a final call. The exact metric stack varies by app, but the principle does not. Paywall analysis should continue past the tap on "Continue."
If your team needs a common language for that post-purchase review, align on subscription business metrics such as renewals, churn, and realized revenue.
A higher-converting paywall can still be the wrong paywall if it pulls in lower-value subscribers.
Three pitfalls that keep repeating
Peeking before the test is mature
Daily result checking is fine. Daily decision-making is where teams get into trouble.
Set the sample target, minimum runtime, and decision criteria before launch. Then stick to them unless there is a tracking failure, billing issue, or customer-facing bug. A well-designed test loses value fast when the team starts calling winners from partial data.
Pooling unlike audiences
Global averages hide local behavior. Country, platform, acquisition source, and new versus returning user status can all change the outcome.
The common failure pattern is simple. iOS responds well to an annual-first layout, Android does not. English-speaking markets like direct price framing, another region responds better to value framing. A single blended result makes the variant look neutral, and the team misses the underlying pattern. Segment reads should be part of the standard review, not a rescue step after rollout.
Treating implementation errors as user behavior
Some losses are not strategic. They are instrumentation bugs that look like learning.
Examples show up every week: exposure events fire before the paywall renders, restore flows are counted as fresh conversions, product IDs differ between iOS and Android variants, or a fallback paywall appears when remote config times out but still gets attributed to the test. If analytics and billing are disconnected, those issues can sit in production long enough to contaminate the result.
Engineers should verify event order and product mapping before analysis starts. Product managers should confirm that the variant users saw matches the variant named in the report. Growth teams should sanity-check conversion, revenue, and refund patterns against raw store data. That cross-functional review catches a surprising number of false winners.
Shipping Winners and Building an Iteration Loop
When a variant wins, don't turn the result into a victory lap. Turn it into a controlled rollout.
The safe move is a progressive release while you watch the same guardrails that mattered during the experiment. If something breaks in entitlement handling, support volume, or renewal quality, you'll catch it before the entire audience is exposed.
Roll out with discipline
A good rollout process is simple:
- Document the winner: Save the exact hypothesis, eligibility rules, variant details, and decision criteria.
- Ramp deliberately: Increase exposure in stages while monitoring purchase integrity and post-purchase behavior.
- Keep a rollback path: Remote rollback matters if a hidden issue appears under broader traffic.
- Check segmented performance: Don't assume the global winner should replace every regional experience.
Country-level judgment is especially important here. One of the most useful pieces of guidance in mobile paywall A/B testing is to test separately within each country because foreign exchange rates, purchasing power, and local market dynamics can cloud the result, as explained in RevenueCat's price testing guide.
Losing tests still pay for themselves
The best teams don't only archive wins. They archive invalidated assumptions.
A failed experiment can teach you that users understand your pricing just fine; the issue is timing. It can show that design polish wasn't the blocker, but proof was. It can tell engineering that instrumentation was incomplete. It can tell product that one audience should never have been pooled with another.
The output of a paywall experiment isn't just a winner. It's a sharper model of user intent, price sensitivity, and purchase friction.
That learning loop is what compounds. Test quality improves, cross-functional trust improves, and the backlog gets smarter. Over time, mobile paywall A/B testing becomes less about chasing isolated lifts and more about building a reliable monetization system.
If your team wants one place to design in-app flows, run experiments, track campaign results, and manage billing and entitlements across iOS, Android, React Native, Flutter, Unity, and Unreal, take a look at Nuxie.